


 Sécurité 100 % vérifiée | Aucun abonnement requis | Aucun logiciel malveillant
Sécurité 100 % vérifiée | Aucun abonnement requis | Aucun logiciel malveillant

Si vous êtes un professionnel qui travaille dans des domaines nécessitant des transcriptions rapides et précises, l'intégration d'API de synthèse vocale dans votre flux de travail doit être ce dont vous avez besoin. Heureusement, bon nombre de ces API offrent une option gratuite, ce qui vous permet de les utiliser pour rationaliser votre processus de transcription sans grever votre budget.
Nous avons donc dressé une liste des meilleures API de synthèse vocale gratuites disponibles, avec leurs principales caractéristiques, leurs limites et la manière de les intégrer dans vos projets. Même si vous estimez que ces options ne répondent pas à vos besoins, nous vous proposons également d'autres recommandations susceptibles de mieux répondre à vos exigences.

Dans cet article
Partie 1. Meilleure API Speech-to-Text gratuite pour la transcription audio
Avec la demande croissante de transcription audio dans divers domaines tels que la création de contenu, l'éducation et les entreprises, une question fréquente que posent de nombreux utilisateurs est la suivante : « Quelles sont les API gratuites ou les services en ligne pour la conversion speech-to-text ? »
Les API de speech-to-text sont essentielles pour que les développeurs puissent intégrer la fonctionnalité speech-to-text dans leurs applications. Pour répondre à ce besoin, nous nous penchons sur un aperçu approfondi des meilleures API de speech-to-text gratuites disponibles aujourd'hui. Parmi elles, on peut citer Google Cloud Speech-to-Text, Microsoft Azure Speech Service, Speechmatics, AssemblyAI et AWS Transcribe.
1. Google Cloud Speech-to-Text API
L'API Google Cloud Speech-to-Text est une partie de la suite Google Cloud, conçue pour convertir l'audio en transcriptions textuelles précises. Grâce à des API conviviales, les développeurs peuvent intégrer des fonctions de reconnaissance vocale dans leurs applications. Pour utiliser gratuitement cette API de speech-to-text, Google offre aux utilisateurs 60 minutes de transcription gratuite. Les nouveaux utilisateurs peuvent également explorer Speech-to-Text et d'autres produits Google Cloud avec jusqu'à 300 dollars de crédits gratuits.
Principales fonctionnalités :
- Il exploite Chirp, le modèle vocal avancé de Google Cloud, entraîné sur des millions d'heures de données audio et des milliards de phrases de texte.
- Il est compatible avec 125 langues et variantes, ce qui le rend adapté à une base d'utilisateurs diversifiée.
- Fournit une sélection de modèles formés adaptés à des cas d'utilisation spécifiques, notamment la commande vocale, la transcription d'appels téléphoniques et la transcription vidéo.
- Utilise des techniques d'adaptation du modèle pour améliorer la précision des mots fréquemment utilisés, élargir le vocabulaire pour la transcription et améliorer les performances dans les environnements audio bruyants.
Limites:
- La version gratuite ne permet que 60 minutes de transcription par mois. Il peut être insuffisant pour des projets plus importants ou des besoins de transcription fréquents.
- Moins pratique pour ceux qui ne connaissent pas les services Google Cloud. Vous devez télécharger les fichiers audio dans un Google Cloud Storage Bucket avant la transcription.
- Les fonctions de personnalisation avancées peuvent ne pas être entièrement accessibles dans la version gratuite.
Idéal pour: Besoins de transcription limités, tels que ceux des petites entreprises ou des indépendants qui transcrivent de courtes interviews, des podcasts ou des réunions.
2. Microsoft Azure Speech API
L'API Microsoft Azure Speech fait partie de la suite de services cognitifs Azure. Pour l'utiliser gratuitement, Microsoft Azure Speech API propose un niveau gratuit avec une utilisation limitée. Ce niveau est idéal pour les petits projets, les tests et l'apprentissage. Il comprend des fonctions telles que la transcription en temps réel et des modèles vocaux personnalisables. Vous pouvez consulter la page de tarification de Microsoft Azure pour plus de détails.
Principales fonctionnalités
- Extraction de l'historique de chaque point d'accès à la demande de ce point d'accès spécifique.
- Accédez au manifeste des modèles que vous créez pour mettre en place des conteneurs sur site.
- Uploader des données à partir de comptes de stockage Azure à l'aide d'un URI de signature d'accès partagé (SAS)
- Utilisez vos propres comptes de stockage pour gérer les journaux, les fichiers de transcription et d'autres données.
- Transcription par lots de fichiers audio à partir de plusieurs URL ou d'un conteneur Azure
Limites
- Le niveau gratuit ne permet d'héberger qu'un seul modèle vocal personnalisé par mois et seulement 5 heures audio gratuites par mois.
- Si la transcription d'Azure est généralement précise, elle peine parfois à épeler les mots correctement
- La configuration initiale de l'API Azure Speech peut s'avérer complexe
Idéal pour: Les secteurs comme la santé, la finance ou les services juridiques où une terminologie spécialisée est fréquemment utilisée.
3. Speechmatics
Speechmatics propose une API de speech-to-text avec un plan gratuit généreux, offrant aux utilisateurs 8 heures de transcription par mois. Ce plan comprend 4 heures pour le traitement en bloc et 4 heures supplémentaires pour la transcription en temps réel. Conçue pour être flexible, Speechmatics s'adresse à diverses applications, de la production de médias au service à la clientèle. Vous pouvez tirer parti de ses algorithmes avancés d'apprentissage automatique pour obtenir une grande précision et des résultats fiables, même dans des environnements audio difficiles.
Principales fonctionnalités
- Compatible avec une cinquantaine de langues, il offre une couverture étendue des différents accents et dialectes.
- L'API permet une transcription en temps réel avec une latence inférieure à une seconde.
- Identifie automatiquement la langue parlée
- Chaque mot de la transcription est accompagné d'un timestamp précis
- Exporter les transcriptions en tant que sous-titres SRT
Limites
- Sa mise en place implique la configuration d'interfaces personnalisées, ce qui le rend plus adapté aux entreprises disposant de ressources techniques.
- Il ne convient pas aux petites entreprises ou aux projets en raison des exigences techniques.
Idéal pour: Besoins de transcription des entreprises à grande échelle.
4. AssemblyAI
AssemblyAI fournit des modèles vocaux assistés par l'IA par l'intermédiaire d'une API. Si vous êtes un nouvel utilisateur, vous recevrez un crédit gratuit de 50 $ pour commencer. Cette API prend en charge diverses tâches liées aux données vocales. Parmi eux figurent la reconnaissance du locuteur, la détection des sujets, l'analyse des sentiments et la synthèse de texte. Deux options de Speech-to-Text sont disponibles : « Meilleure » pour une grande précision et « Nano » pour une transcription économique.
Principales fonctionnalités
- La diarisation des locuteurs permet d'identifier et de séparer les différents locuteurs dans un enregistrement audio.
- Orthographe et vocabulaire personnalisés : vous pouvez saisir des mots personnalisés ou une terminologie spécialisée pour une transcription précise.
- Censure automatique du langage inapproprié et application d'une ponctuation et d'une casse correctes pour une meilleure lisibilité.
Limites
- La plateforme offre moins de langues que certains concurrents
- Les bugs et problèmes occasionnels peuvent prendre du temps à être traités ou résolus.
- L'outil peine souvent à assurer la précision de la transcription lorsque l'audio contient des bruits de fond ou des perturbations importants.
Idéal pour: Transcription de réunions, d'entretiens ou de podcasts impliquant plusieurs intervenants.
5. AWS Transcribe
Amazon Transcribe, un service d'AWS, permet aux nouveaux utilisateurs de bénéficier d'une heure de transcription gratuite chaque mois pendant leur première année. Ce service permet aux utilisateurs de convertir des fichiers audio en texte pour divers besoins, mais il nécessite que les fichiers audio soient stockés sur Amazon S3.
Principales fonctionnalités
- Ponctuation et options de formatage
- Vocabulaire personnalisé pour les termes spécifiques à l'industrie
- Identification de plusieurs intervenants
- Transcrire en texte des flux audio en direct ou des discours préenregistrés
Limites
- Nécessite un stockage audio sur Amazon S3
- Peut manquer des mots spécifiques, en particulier des noms propres ou des entités nommées (NER)
Idéal pour: Entreprises ayant besoin d'une transcription automatisée pour les réunions, les médias ou l'assistance à la clientèle
Partie 2. Comment démarrer l'intégration de l'API Speech-to-Text ?
Pour commencer à intégrer l'API Speech-to-Text, chaque service fournit généralement une documentation détaillée et des ressources pour guider les développeurs tout au long du processus de configuration. Vous commencez généralement par créer un compte auprès du fournisseur. Ensuite, générez une clé API qui donne accès au service.
À titre de démonstration, l'une des API de reconnaissance vocale les plus populaires, Google Cloud Speech-to-Text, fournit ici la documentation de l'API Google Cloud Speech-to-Text. Le processus comprend plusieurs étapes clés :
- Créez un projet Google Cloud : Ouvrez un compte Google Cloud et créez un nouveau projet dans la Google Cloud Console. Ce projet gère les ressources liées à l'API.
- Activer l'API Speech-to-Text : Accédez à la section API & Services, recherchez l'API Speech-to-Text et activez-la pour votre projet.
- Générer les identifiants de l'API : Créez un compte de service et générez une clé API, que vous utiliserez pour authentifier vos demandes. Téléchargez le fichier clé (généralement au format JSON) pour stocker vos informations d'identification.
- Configurer la bibliothèque client : Installer les bibliothèques client nécessaires (telles que Python, Java ou Node.js) pour interagir avec l'API de manière programmatique. Les bibliothèques client simplifient les demandes d'API et le traitement des réponses.
- Écrire du code pour transcrire de l'audio : Utilisez la clé API et la bibliothèque client pour écrire du code qui convertit le son en texte en envoyant les données audio aux serveurs de Google Cloud pour qu'elles soient traitées.
Regardez ici le tutoriel complet sur l'intégration de l'API speech-to-text gratuite de Google Cloud dans votre application.
Partie 3. Meilleure solution pour utiliser le speech-to-text sans intégration d'API
Tous les utilisateurs ou toutes les entreprises n'ont pas besoin d'intégrer des API, car la configuration peut être complexe, longue et parfois inutile pour les petits projets ou les utilisateurs individuels. En revanche, il existe un autre moyen de convertir la parole en texte sans intégration d'API. L'une de ces options est la fonction Speech-to-Text de Wondershare Filmora.
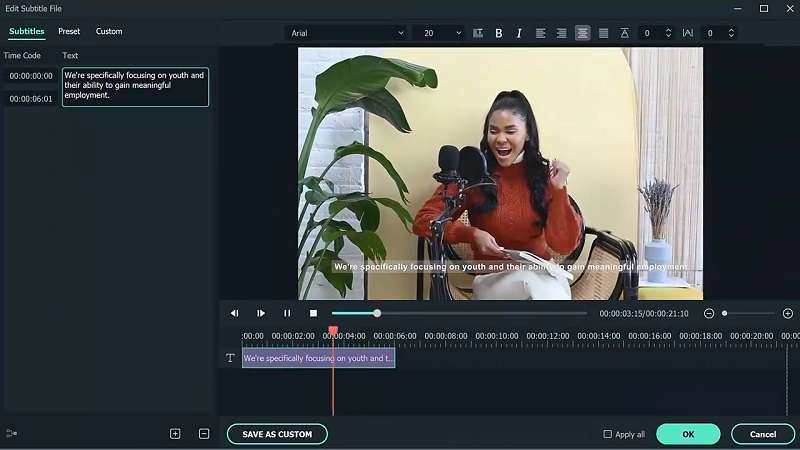
Fonctionnalité Speech-to-Text de Filmora
Filmora est un outil d'édition vidéo populaire qui intègre une fonction de speech-to-text. Vous pouvez l'utiliser pour convertir des mots prononcés dans des fichiers audio ou vidéo directement en texte. Cette fonction est une solution simple pour générer rapidement des sous-titres, des légendes ou des transcriptions. Vous n'avez pas à vous soucier de la transcription manuelle ou de configurations complexes - le processus est entièrement automatisé.
De plus, si vous travaillez sur des projets multilingues ou si vous devez transcrire du contenu dans différentes langues, le speech-to-text de Filmora prend également en charge plusieurs langues. Ils comprennent l'anglais, le français, l'espagnol, l'indonésien, l'hindi, le japonais et bien d'autres encore.
Quand choisir la fonction speech-to-text de Filmora plutôt que l'intégration API ?
- Utilisateurs non techniques : Si vous n'avez pas de connaissances techniques ou d'équipe de développement, l'interface conviviale de Filmora élimine la nécessité d'une intégration API.
- Projets à exécution rapide : Si vous avez besoin de transcrire rapidement du contenu pour des sous-titres, des légendes ou des projets vidéo de courte durée, le processus entièrement automatisé de Filmora vous permet de gagner du temps par rapport à la configuration manuelle des services API.
- Travailler avec du contenu vidéo : Puisque Filmora combine les capacités d'édition vidéo et de speech-to-text en une seule plateforme, vous pouvez appliquer le texte transcrit directement à vos projets vidéo pour les sous-titres, les légendes ou les transcriptions sans passer d'un outil à l'autre.
Utilisation étape par étape du speech-to-text avec Filmora
Étape 1: Ouvrir Filmora et importer le fichier audio
Assurez-vous que la dernière version de Filmora est installée sur votre ordinateur. Ensuite, lancez Filmora et sélectionnez Nouveau projet pour créer un nouveau projet.
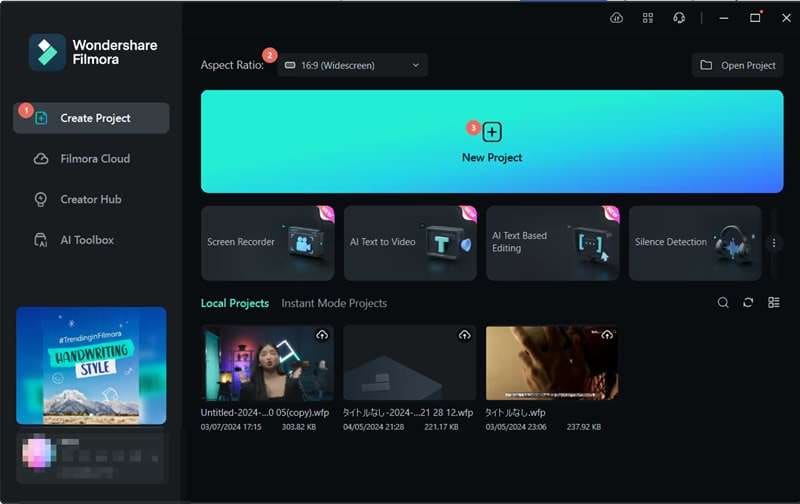
Pour uploader votre fichier audio, cliquez sur Importer et choisissez le fichier sur votre ordinateur.
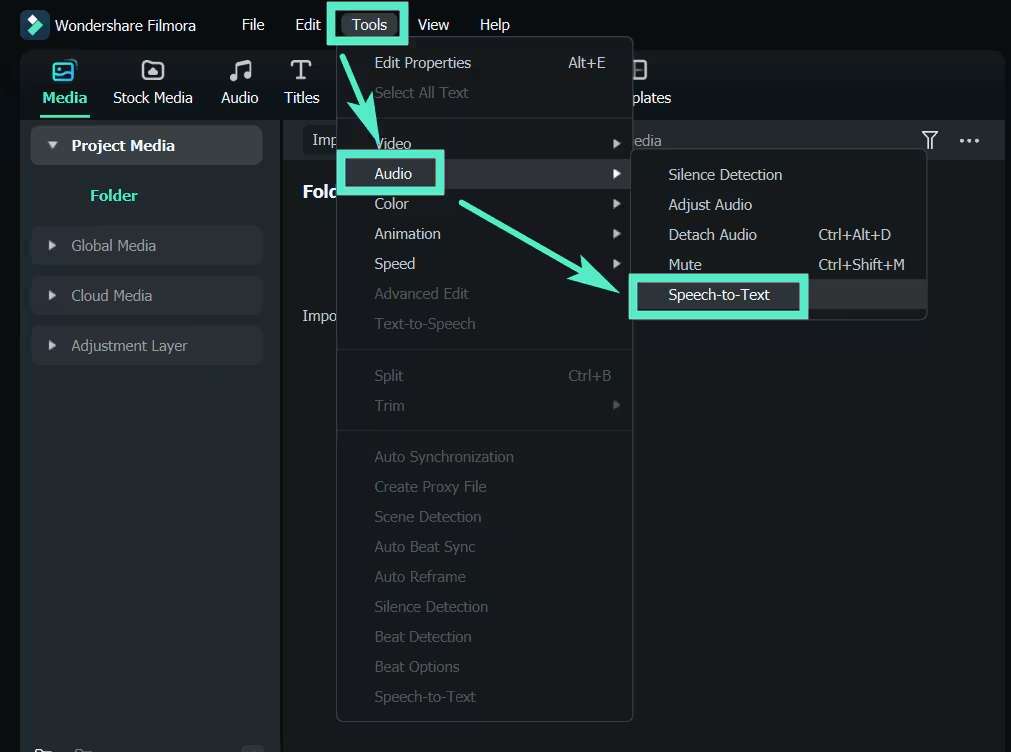
Étape 2: Accéder à l'outil Speech-to-Text
Une fois votre fichier audio importé, faites-le glisser sur la timeline. Pour activer l'outil speech-to-text, sélectionnez la piste audio sur la timeline. Ensuite, allez dans Outils > Audio > Speech-to-text.
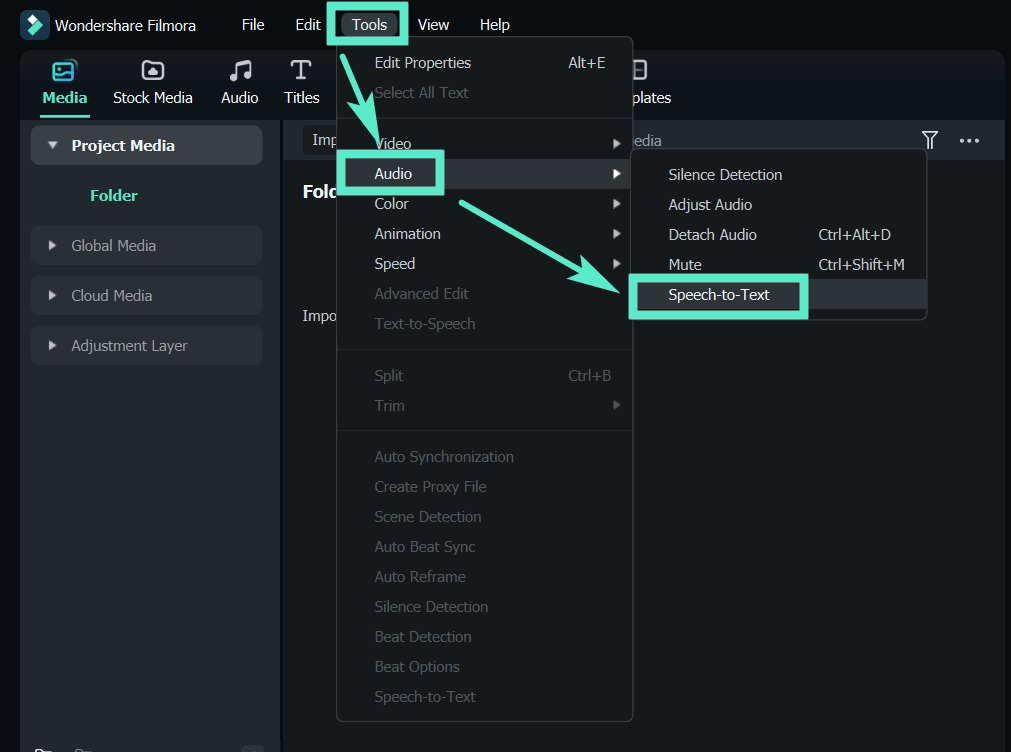
Étape 3: Paramétrage des préférences de transcription
Une fenêtre de configuration de la fonction speech-to-text apparaît. Ici, vous pouvez sélectionner la langue du fichier audio que vous transcrivez. Si vous ne souhaitez pas que le discours soit traduit, sélectionnez l'option « Pas de traduction » dans la section « Langue à traduire ».
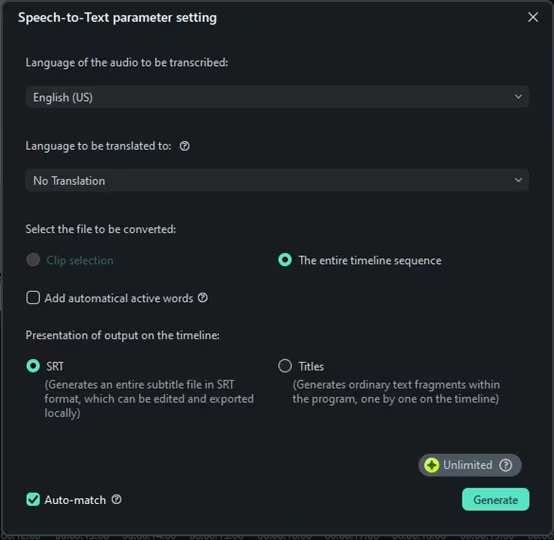
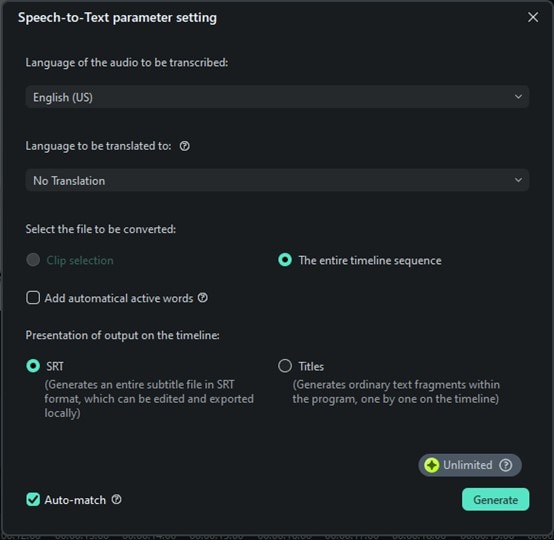
Vous pouvez également décider de transcrire uniquement le clip audio sélectionné ou la totalité de la timeline. Ensuite, choisissez le format de sortie comme fichier SRT.
Étape 4: Commencer la transcription de l'audio
Une fois tous les paramètres définis, cliquez sur le bouton Générer. Filmora traitera l'audio et créera la transcription. Une fois la transcription effectuée, le fichier de transcription sera disponible dans l'onglet Média.
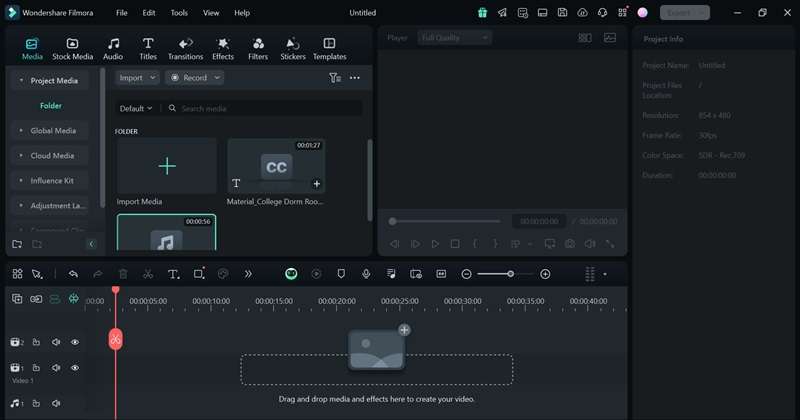
Étape 5: Modifier la transcription
Si vous devez ajuster la transcription, double-cliquez sur le fichier de transcription généré pour ouvrir l'interface d'édition. Ici, vous pouvez revoir le texte et apporter les corrections nécessaires.
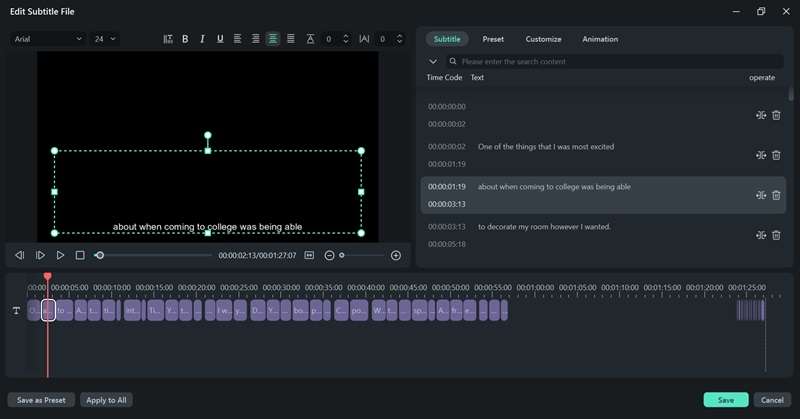
Étape 6: Enregistrer ou ajouter la transcription à votre projet
Après avoir effectué toutes les modifications nécessaires, vous pouvez exporter la transcription sous la forme d'un fichier SRT. Faites un clic droit sur la piste de transcription du texte sur la timeline et sélectionnez « Exporter le fichier de sous-titres ».
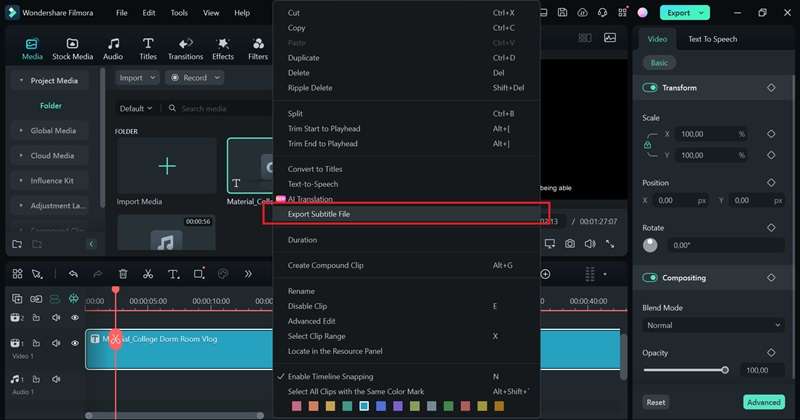
Conclusion
Grâce aux API gratuites dédiées au speech-to-text, les développeurs peuvent intégrer la transcription dans leurs applications sans avoir à supporter des coûts élevés. Dans l'article d'aujourd'hui, nous avons passé en revue certains des meilleurs outils du marché, notamment Google Cloud Speech-to-Text, Microsoft Azure, Speechmatics, AssemblyAI et AWS Transcribe. Ces options gratuites constituent un bon point de départ, que vous travailliez sur des projets à petite échelle ou que vous testiez la reconnaissance vocale dans le cadre de votre projet.
Toutefois, si vous recherchez une solution moins technique, la fonction Speech-to-Text intégrée à Filmora peut constituer une excellente alternative. Il simplifie le processus, en particulier pour les créateurs de vidéos ou les entreprises qui ont besoin d'une transcription rapide sans la complexité des intégrations API.
