
 Sécurité 100 % vérifiée | Aucun abonnement requis | Aucun logiciel malveillant
Sécurité 100 % vérifiée | Aucun abonnement requis | Aucun logiciel malveillant


Avez-vous déjà réfléchi à la manière dont vous pouvez effectuer une recherche vocale sur Google ? La technologie de reconnaissance vocale automatique (ASR) vous permet de contrôler votre téléphone avec votre voix,même lorsque vous êtes occupé.
L'ASR peut sembler n'être qu'un simple outil de conversion de la parole en texte, mais c'est bien plus que cela. Le speech-to-text de base se contente de convertir les mots prononcés en texte. Il nécessite souvent une prononciation claire et un bruit de fond limité pour obtenir des résultats précis.
Toutefois, l'ASR, quant à elle, utilise l'intelligence artificielle (IA) et l'apprentissage automatique pour améliorer la précision, reconnaître différents accents, filtrer le bruit de fond et même comprendre le contexte. Par conséquent, il peut être intégré dans des outils d'assistants virtuels, des robots de service clientèle, la recherche vocale, etc.
Cet article vous montrera comment fonctionne l'ASR et comment utiliser les systèmes de reconnaissance vocale automatique selon vos différents besoins.
Dans cet article
Partie 1 : Qu'est-ce qu'un système de reconnaissance vocale automatique et comment fonctionne-t-il ?

La reconnaissance vocale automatique convertit les mots prononcés en texte en utilisant l'IA, l'apprentissage automatique et des modèles linguistiques pour traiter et interpréter la parole. Ils sont à la base des assistants vocaux comme Siri et Alexa, un élément clé des services de transcription, de l'analyse des centres d'appels et même des outils de traduction linguistique en temps réel.
Les systèmes ASR analysent l'entrée audio, identifient les modèles de parole et les traduisent en texte. Toutefois, le processus n'est pas aussi simple que d'écouter et de taper les mots du locuteur.
Comment fonctionnent les systèmes ASR ?
- Tout d'abord, un système ASR enregistre votre parole en utilisant un microphone. Dans certains cas, vous pouvez télécharger un fichier audio.
- Ensuite, l'audio est nettoyé pour réduire le bruit et améliorer la clarté.
- Puis, le système analyse l'audio en trames et extrait des fonctionnalités clés telles que la hauteur, le ton et le rythme.
- Le système ASR fait correspondre les fonctionnalités extraites avec son modèle acoustique. Les modèles acoustiques sont entraînés à reconnaître les modèles de parole et les phonèmes.
- Les modèles linguistiques sont utilisés pour prédire les combinaisons de mots les plus probables sur la base de la grammaire, des phrases courantes et des règles de syntaxe. Par exemple, si quelqu'un dit « reconnaître la parole », un système ASR s'assure qu'il ne le confond pas avec « détruire une belle plage ».
- Enfin, le système utilise un algorithme de décodage pour faire correspondre l'audio traité avec la sortie la plus probable en fonction des données audio et linguistiques. Tout cela se produit en quelques nanosecondes.
Les meilleurs systèmes ASR utilisent l'apprentissage profond pour peaufiner leurs prédictions au fil du temps, en apprenant des corrections de l'utilisateur et en augmentant leur précision à chaque utilisation.
Partie 2 : Mythes courants sur les systèmes ASR vs. Faits
La reconnaissance vocale automatique a progressé et s'est intégrée dans différents secteurs au fil des ans. Mais il existe encore plusieurs idées fausses sur son fonctionnement et son utilisation.

Maintenant, séparons les faits de la fiction !
| Mythes | Faits |
| Les systèmes ASR sont précis à 100%. | Même les systèmes ASR les plus avancés, comme ceux utilisés par Google ou OpenAI, peuvent faire des erreurs. Les bruits de fond et les accents trop prononcés peuvent être la cause des erreurs. Ainsi, bien que la plupart des modèles assistés par IA aient gagné en précision, ils nécessitent toujours une supervision, une révision et des outils de post-édition, même si ce n'est pas souvent le cas. |
| Les systèmes ASR comprennent les langues comme les humains | Les systèmes ASR ne comprennent pas le langage comme les humains. Ils analysent les modèles et les probabilités dérivés de grandes séries de données. Ils fonctionnent grâce à des modèles statistiques - les modèles de Markov cachés (HMM) ou les réseaux neuronaux profonds avancés utilisés aujourd'hui - qui associent les sons aux mots. Ainsi, bien qu'ils imitent les humains, ils n'ont pas une véritable compréhension du sens des mots transcrits |
Partie 3 : Comment utiliser la technologie de reconnaissance vocale automatique
Comme mentionné, la technologie de reconnaissance vocale automatique va au-delà des commandes vocales et de la simple conversion de la voix en texte. Elle est intégrée à différents outils pour faciliter les processus dans diverses industries. Vous trouverez ci-dessous le processus détaillé de l'application de la technologie ASR dans le montage vidéo.
Logiciel de montage vidéo avec ASR - Filmora
La technologie ASR a permis aux éditeurs et créateurs de vidéos d'ajouter plus facilement des sous-titres, des transcriptions et des voix off aux vidéos. Les outils de montage vidéo comme Filmora de Wondershare intègrent des systèmes ASR qui facilitent cette opération tout en offrant d'autres options de montage.

Filmora est un outil de montage vidéo qui offre un montage de niveau professionnel avec des fonctionnalités intuitives qui rationalisent votre processus de montage. Sa fonctionnalité de détection de locuteur assistée par IA utilise l'ASR pour identifier les différents locuteurs d'une vidéo et les transcrire automatiquement pour créer des sous-titres / légendes textuels. Cela permet aux monteurs vidéo d'éditer les dialogues plus rapidement, ce qui leur fait gagner du temps.
Filmora pour mobile Filmora pour mobile Filmora pour mobile Filmora pour mobile Filmora pour mobile
Montez des vidéos sur votre téléphone portable en un clic !
- • Puissante et nouvelle fonctionnalité IA.
- • Montage vidéo convivial pour débutants.
- • Montage vidéo complet pour les professionnels.
 4.5/5 Excellent
4.5/5 Excellent

Voici comment utiliser la technologie ASR mobile de Filmora pour rationaliser votre processus de montage vidéo.
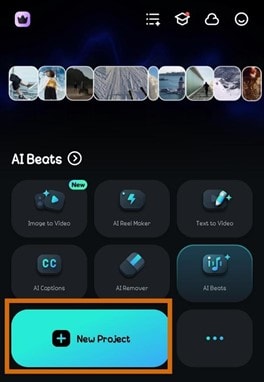
- Étape 1 : Ouvrez Filmora sur votre téléphone et sélectionnez Nouveau projet. Importez la vidéo que vous voulez éditer dans Filmora.
 téléchargement sécurisé
téléchargement sécurisé

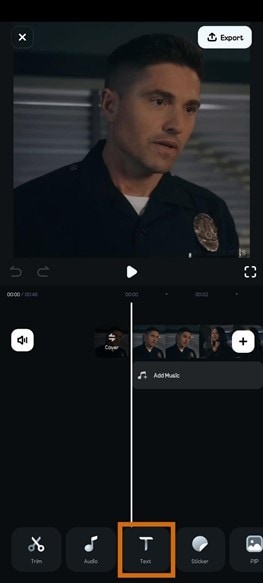
- Étape 2 : cliquez sur Texte et sélectionnez sous-titres IA.
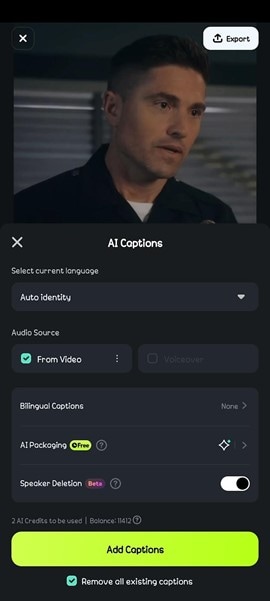
- Étape 3 : Vous pouvez choisir d'indiquer la langue parlée dans votre vidéo ou laisser Filmora l'identifier automatiquement. Cliquez sur Ajouter des sous-titres. Filmora peut prendre quelques secondes pour détecter les locuteurs de votre vidéo et générer des sous-titres.
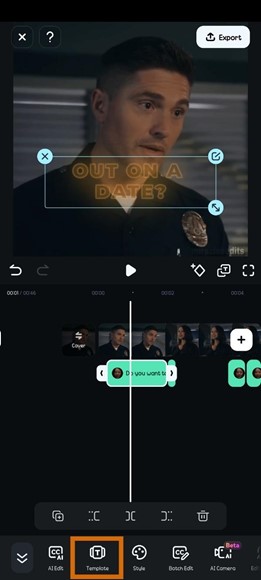
- Étape 4 : cliquez sur Modèle pour sélectionner un modèle pour vos sous-titres.
- Étape 5 : Vous pouvez sélectionner les sous-titres auxquels appliquer le modèle. Vous pouvez également appliquer différents modèles à différentes sous-titres. Cliquez sur Appliquer.
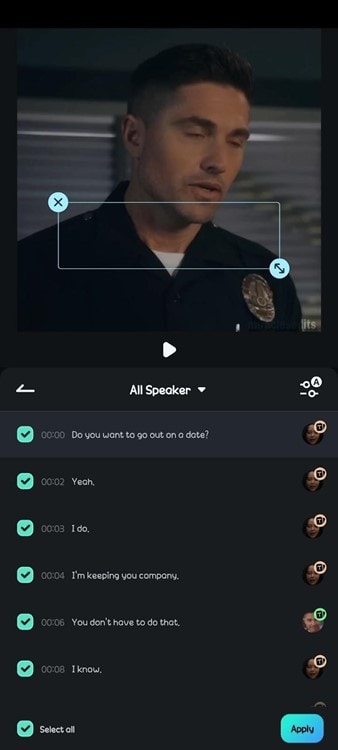
- Étape 6 : Déplacez les sous-titres sur la vidéo pour ajuster leur emplacement. Vous pouvez modifier le texte du sous-titre en sélectionnant Style dans la barre d'outils.
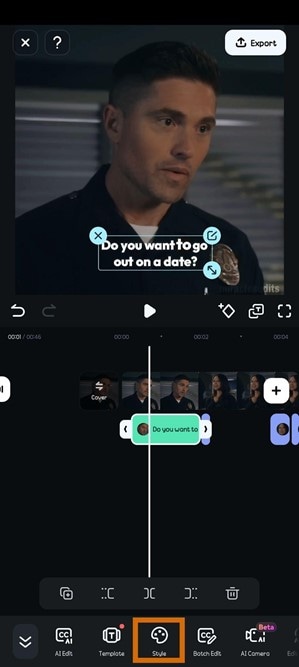
- Étape 7 : Cliquez sur Modifier la parole pour apporter d'éventuelles corrections et améliorer la précision de la parole. Faites correspondre la parole éditée au locuteur dans la vidéo ou clonez une voix. Une fois que c'est fait, cliquez sur Mise à jour de la parole. Cela devrait prendre quelques minutes.
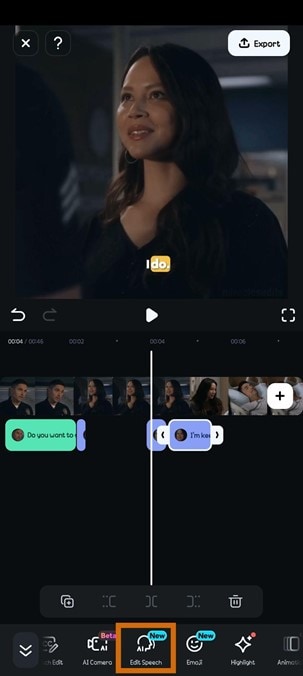
L'équivalent de cette fonction sur le bureau de Filmora est la fonction Speech-to-Text. Voici comment utiliser l'intégration ASR de Filmora sur sa version de bureau.
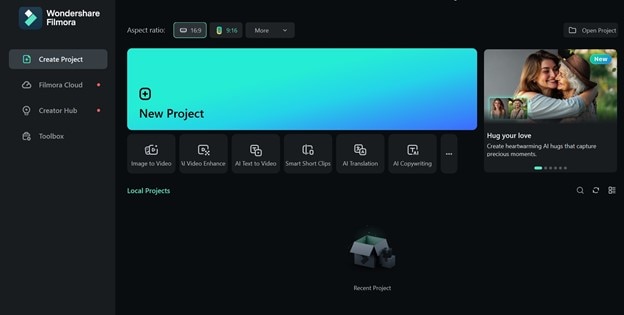
- Étape 1 : Lancez Filmora sur votre ordinateur. Cliquez sur Nouveau projet sur l'écran d'accueil. Importez votre vidéo dans Filmora et chargez-la sur la timeline.
 téléchargement sécurisé
téléchargement sécurisé - Étape 2 : Cliquez avec le bouton droit de la souris sur la vidéo dans la timeline et sélectionnez Speech-to-Text.
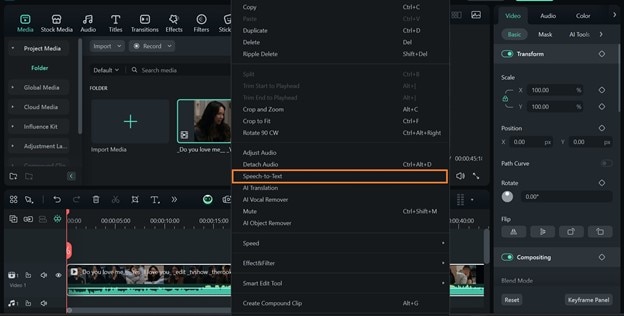
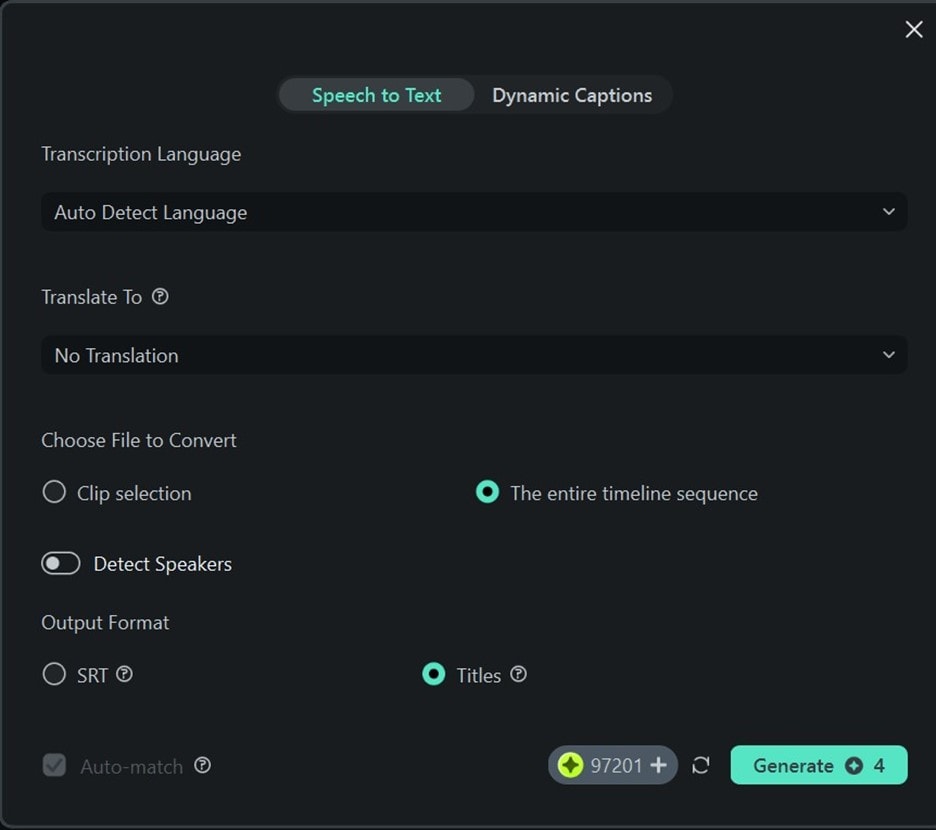
- Étape 3 : Assurez-vous de définir le format de sortie sur Titres et cliquez sur Générer.
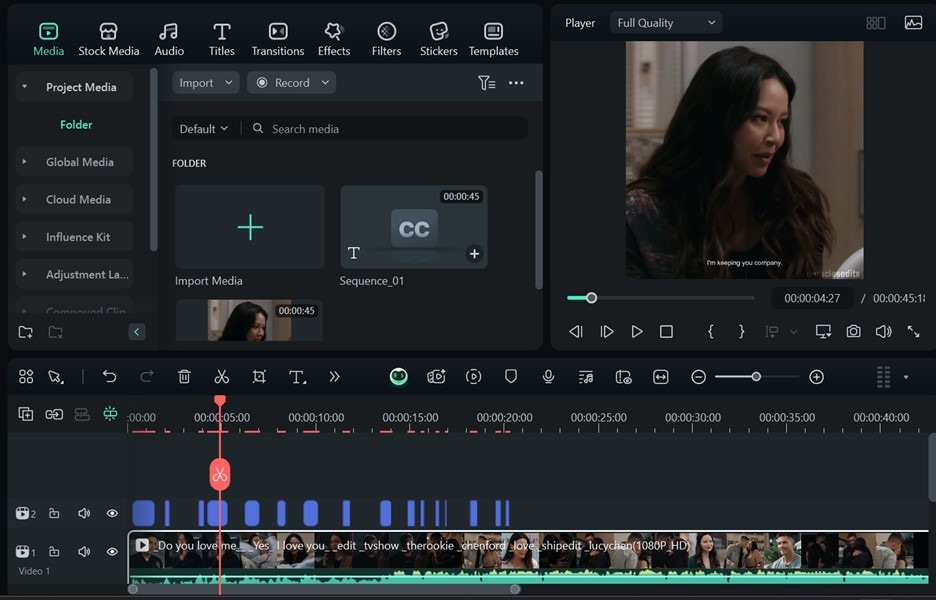
- Étape 4 : Le texte transcrit sera ajouté à votre vidéo.
Partie 4 : Défis liés aux applications ASR & Progressions futures

La technologie de la reconnaissance vocale automatique a rendu la vie et le travail plus faciles et plus pratiques. Toutefois, elle doit encore relever plusieurs défis qui affectent son utilisation et sa précision.
- Accents et dialectes différents : Les variations de prononciation, d'intonation et d'argot peuvent entraîner des interprétations erronées.
- Mauvaise qualité audio et bruits de fond : Les sons qui se chevauchent, les bruits de fond et les échos peuvent entraîner des erreurs de transcription et réduire les performances de l'ASR.
- Homophones : Les mots qui se prononcent de la même manière mais qui ont des significations différentes peuvent poser problème à certains systèmes ASR. Par exemple, des mots comme « there », « their », « two » et « too » peuvent être facilement confondus, surtout sans indices contextuels. Cela peut conduire à des transcriptions inexactes.
Une solution potentielle à cela est de développer des modèles acoustiques améliorés ou plus avancés qui tiennent compte d'une plus grande variété d'accents et de dialectes. De plus, les développeurs pourraient intégrer le traitement du langage naturel (NLP) dans des systèmes ASR moins avancés. Cela leur permettrait de tenir compte des contextes et de différencier les homophones avec plus de précision.
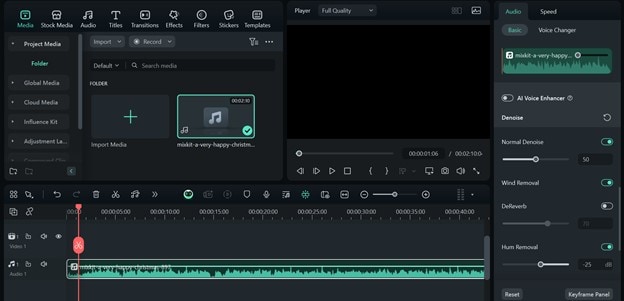
Amélioration de la qualité audio avec Filmora
Pour les outils ASR qui permettent de télécharger des clips audio, vous pouvez résoudre le problème du bruit de fond et de la faible qualité audio en utilisant des outils comme Filmora. Voici comment ;
Ouvrez Filmora et téléchargez le fichier audio enregistré. Glissez et déposez l'audio sur la timeline. Cliquez sur le clip audio sur la timeline et allez dans le panneau d'édition à votre droite. Activez la normalisation automatique. Activez le débruitage, la suppression du vent et la suppression du bourdonnement pour obtenir un audio clair. Puis, exportez le clip audio. Assurez-vous de définir le format d'exportation sur mp3.
Conclusion
La technologie de la reconnaissance vocale automatique a changé la façon dont nous interagissons avec la technologie. De la transcription basique à la spécialisation avancée dans diverses industries, l'ASR a augmenté notre productivité et efficacité.
Filmora, par exemple, a rendu le sous-titrage vidéo plus facile et plus fiable grâce à sa fonction de détection de locuteur. Combinez cela avec sa fonctionnalité d'amélioration audio, et vous aurez un outil puissant qui transforme vos vidéos et audio. Malgré les défis auxquels ces systèmes ARS sont confrontés, les progrès futurs promettent une reconnaissance vocale améliorée et perfectionnée.
téléchargement sécurisé 

